
近幾年AI芯片火熱,不讓Nvidia專美于前,英特爾在確定進入10納米時代后更是積極追趕,美國時間20日,英特爾公布首款神經網絡處理器Nervana(代號Springhill)相關細節,包含訓練芯片NNP-T與推論芯片NNP-I,加上原有的Xeon在AI芯片陣容越發堅強,技術也開始兼容了起來。
美國時間20日,英特爾在今年Hot Chips大會上公布首款神經網絡處理器Nervana細節,如其名,這是2016年英特爾收購包含Nervana幾家新創公司的成果。Nervana處理器分為訓練芯片NNP-T與推論芯片NNP-I。
訓練用的Nervana NNP-T,主打可編程與靈活性,并強調可從頭建構大規模深度學習模型,且盡可能訓練電腦在給定的能耗預算內快速完成任務,也無需傳統技術的龐大開銷。
NNP-T支援了Google TPU Tensorflow架構特有的運算格式“bfloat16”,bfloat16截斷既有的32位元float32的前16位,僅留下后16位所組成,在許多機器學習模型可以容忍較低精確度計算、不需降低收斂準確率的情況下,許多模型使用bfloat16達到的收斂準確率結果與一般使用的32位元浮點(FP32)計算數值的結果一樣,降低精度其實能讓存儲器效率取得較佳的平衡,從而訓練與部署更多的網絡、降低訓練所需的時間,有較好的效率與靈活性,而這是英特爾首次將bfloat16內建于處理器。
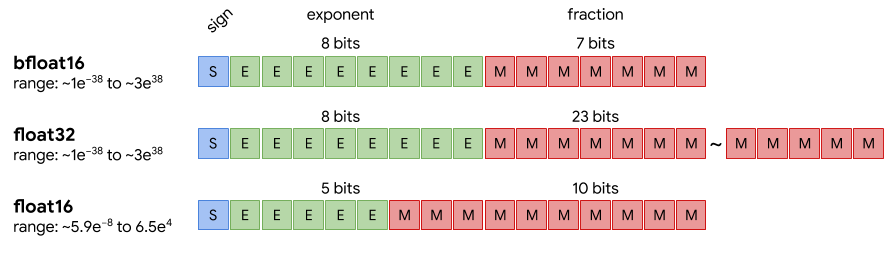
▲bfloat16浮點格式(Source:Google)
另外有趣的是NNP-T其實采用的是臺積電16納米CLN FF+制程,這與一般我們對英特爾自行生產芯片的認知有所差異,而在Nervana被英特爾收購前,第一代Lake Crest就是由臺積電所代工。NNP-T采用臺積電最新的CoWoS(Chip on Wafer on Substrate)封裝技術,將NNP-T的晶粒與四個8GB HBM2存儲器異質整合堆疊2.5D,讓其封裝體積縮小成一個60X60 mm的芯片。

▲Nervana NNP-T采用臺積電16nm CLN FF+制程(Source:Intel)
英特爾同時發表了推論芯片Nervana NNP-I,主要針對大型資料中心市場高效能深度學習推論而生,NNP-I主要基于英特爾10nm Ice Lake處理器,官方強調透過此芯片,可提高每瓦效能,讓企業以更低的成本執行推論運算工作,降低推論大量部署的成本。英特爾指出,NNP-I在功率10瓦下每秒能處理3600張影像,而處理器本身亦擁有高度可編程性,且同時不影響性能與功效。

▲Nervana NNP-I架構(Source:Intel)
NNP-I已與Facebook合作并實際運用在其相關業務上,而NNP-T將于今年底以前針對尤其云端服務商相關的高端客戶送樣,并在2020年之前拓展市場。




