
DeepSeek作為2025年開年最受關注的AI大模型,因其出色的性能、低廉的開發成本和開源生態三大核心優勢,火爆出圈,迅速引爆全球AI熱潮,當前已廣泛應用于端側、教育、金融、辦公、傳媒、醫療、智能汽車、企業服務等多個應用場景。
DeepSeek低成本的解決方案,大幅降低了AI在各行各業應用的技術和成本門檻,為AI的產業化落地提供了更快的路徑,因此催生出了很多本地私有化部署的需求,打造企業和私人專屬AI助手。

一、DeepSeek不同參數量模型的應用場景
DeepSeek R1 融合了先進的推理、成本效益和開源可訪問性,開辟了從科學研究和編碼到交互式聊天機器人和企業自動化等各種應用場景。其透明的思維鏈方法不僅增強了信任,還提供了有關如何做出決策的寶貴見解,使其成為跨多個行業的強大工具。
DeepSeek R1 / R1 zero (671B):具備極高精度與深度推理能力,能解析復雜數據集、法律文件或情報報告,適用于科學研究、金融風險建模等高復雜度場景,也為尖端人工智能研發與通用人工智能(AGI)探索提供了關鍵支撐。
DeepSeek R1 Distill-Qwen 1.5B:輕量級對話 AI、快速代碼生成;移動/邊緣設備測試和原型開發,適合資源受限環境下的快速響應
DeepSeek R1 Distill-Qwen 7B/DeepSeek R1 Distill-Llama 8B/ DeepSeek R1 Distill-Qwen 14B:中規模應用,如高級對話代理、代碼助手及綜合推理任務;通用型應用,如聊天機器人;兼顧響應速度與成本效益,同時保證穩定的推理能力
DeepSeek R1 Distill-Qwen 32B:企業級中、低負荷應用;高質量、細致推理需求場景,如高級科研、金融建模及復雜仿真系統
DeepSeek R1 Distill-Llama 70B:高端研究和數據分析,適用于高級科學等環境研究、藥物發現或需要深度推理和精確輸出的大規模模擬系統。
二、DeepSeek私有化部署的必要性
? 數據安全與隱私保護
本地部署可完全掌控模型運行環境,避免敏感數據外泄,降低數據泄露風險。
? 高效業務流程與可控性
低延遲與穩定性:本地部署可降低網絡延遲,提升實時決策和工業控制等場景的性能表現。
靈活優化:企業可在本地環境中根據業務需求微調或蒸餾大模型,動態調整模型大小和集群規模,滿足多樣化需求。
? 成本可控與靈活性
節省成本:本地部署可減少長期高頻調用云端大模型的費用,便于統一規劃硬件利用率。彈性擴展:企業可自由擴展計算規模,靈活調整硬件配置,確保長期投資的自主性。
? 定制化與個性化能力
深度集成與定制:企業可在本地部署基礎上,與ERP、CRM等業務系統深度集成,對模型進行定制化開發,實現精準內容生成或預測。
私有數據訓練:企業可利用本地數據進行模型訓練或微調,無需上傳至公共云,提高模型針對性和準確率。
三、超擎數智DeepSeek私有化部署方案
隨著DeepSeek系列模型的開源與廣泛的應用,企業級私有化AI算力正成為主流。超擎數智擎天系列AI訓推一體服務器、鋒銳系列AI推理服務器,以澎湃算力和高性能、高可靠、高穩定的極致體驗,提供極簡的DeepSeek本地私有化部署方案,為AI算力推理注入強勁動力,幫助企業搶占AI發展的先機。
擎天系列AI訓推一體服務器型號為CQ7458-L,是超擎數智國內首發的 NVIDIA 新一代L20 AI服務器。擎天系列AI訓推一體服務器基于 Intel 最新Eagle Stream平臺,搭載 NVIDIA L20 GPU,4U8卡 PCIe,采用“283”方案設計,搭載2顆Intel第四代CPU,連接8片L20 GPU、2片CX7 400G NDR網卡和1片BlueField-3 2X200G DPU卡,具備業界領先的性能,可滿足訓練和推理、生成式人工智能、圖形視覺計算、視頻加速應用等各種AI 業務應用需求。

▲超擎數智擎天系列AI訓推一體服務器
鋒銳系列AI推理服務器型號為CQ7258-A,是超擎數智國內獨家發布的 NVIDIA 新一代L20 GPU服務器。鋒銳系列AI推理服務器采用 AMD EPYC 9004 處理器,搭載 NVIDIA L20 GPU,2U4卡 PCIe,采用“142”方案設計,搭載一顆 AMD EPYC 9004 處理器,連接4片L20 GPU、2片CX7 400G NDR網卡,專為滿足企業AI 基礎設施的需求而打造,通過行業領先的GPU、更快的GPU互連及更高帶寬結構提供強大的性能,并支持多達4個雙槽主動或被動GPU可擴展配置,還可以選擇 NVIDIA NVLink® Bridge 來實現性能擴展及更高帶寬,助力加速AI 和高性能計算 (HPC)工作負載。
鋒銳系列AI推理服務器性能出色,所有GPU直接連接到CPU,無需經過PCIe Switch,配備兩張NDR網卡,每張GPU可提供200G 帶寬,大大提高工作效率,能夠充分滿足AI推理、模型微調和高性能計算過程中的強大算力需求。

▲超擎數智鋒銳系列AI推理服務器
針對 DeepSeek 私有化部署的需求,超擎數智憑借資深的技術研發團隊和豐富的項目實施經驗,為用戶提供DeepSeek同款技術、FP8混合精度訓練平臺、InfiniBand網絡底座、高性能GPU服務器,根據用戶需求,高效完成DeepSeek 本地私有化部署,加速大模型訓練、推理邁向全面應用的新時代。超擎數智基于擎天系列AI訓推一體服務器、鋒銳系列AI推理服務器,提供以下三種DeepSeek本地私有化部署方案:

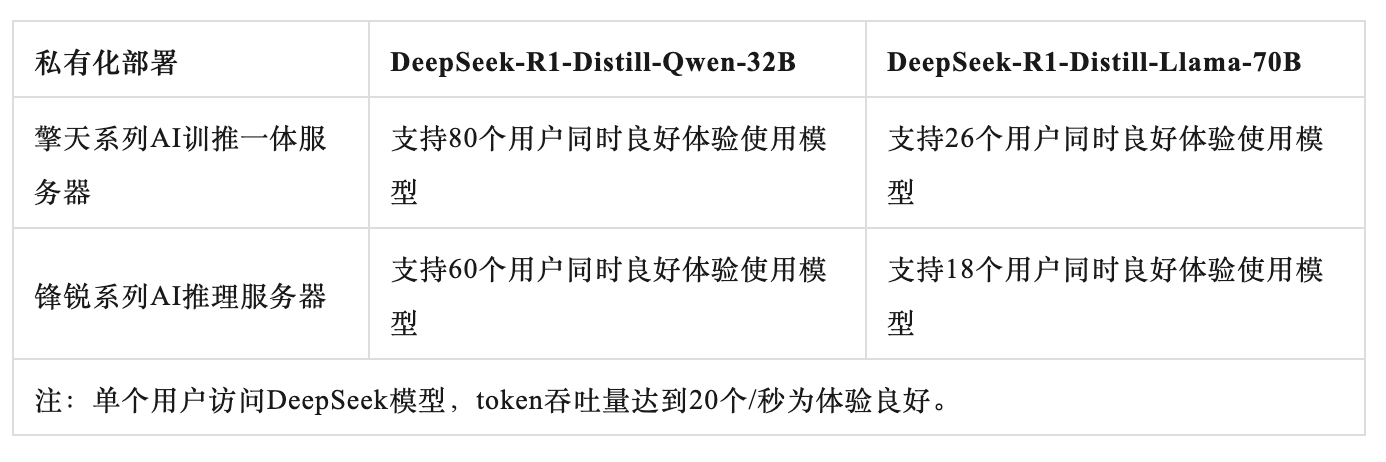
以DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B模型參數為例,采用擎天系列AI訓推一體AI服務器、鋒銳系列AI推理服務器完成DeepSeek本地私有化部署,經超擎數智技術團隊實測的用戶并發訪問與token吞吐量性能表現良好,具體實測數據如下表所示。
四、超擎數智DeepSeek私有化部署增值服務
DeepSeek私有化部署除了算力也離不開高帶寬、低延遲的網絡通信,這種需求不僅影響模型推理速度,還決定了集群整體的可擴展性與穩定性。作為 NVIDIA Compute(GPU)與 Networking(網絡)的雙Elite精英級合作伙伴,超擎數智在算力和網絡領域具有深厚的技術儲備與豐富的項目實戰經驗。公司擁有專業的審計調優技術團隊和交付驗收技術團隊,能夠在硬件選型、網絡架構設計、集群部署及優化等環節為企業提供全方位支持。
在滿足高性能、高可靠、高安全的智能計算需求的同時,超擎數智還通過 CQIS (CHAOQING Infrastructure Service)服務體系,為客戶快速部署并落地 DeepSeek 等大型模型提供保障。這不僅大幅縮短了從立項到上線的周期,也有效降低了對企業內部技術能力的要求,使得各種規模與領域的組織都能受益于大模型帶來的創新價值。
超擎數智以自主研發的AI Engine人工智能開發平臺、NVAIE及定制化AI軟件產品,全面加速用戶人工智能應用的開發和部署,搭配超擎數智擎天系列AI訓推一體服務器、鋒銳系列AI推理服務器,打造開放、高效、易用的人工智能軟件平臺,幫助企業和個人快速完成DeepSeek私有化部署落地。使用TensorRT框架以及Triton推理服務為用戶提供高吞吐、低延遲的模型體驗,在此基礎上,通過技術支持,協助用戶深度挖掘數據價值,從而實現更高精度、更廣覆蓋的AI應用場景。




